Memory mapping improvements
In my previous post I demonstrated initial testing of a memory mapped FPGA-MCU interface bridging from the STM32 FMC peripheral to an APB bus on a Xilinx FPGA.
To stress this interconnect a bit, I pushed 284 Mbps of iperf3 traffic over it. But that wasn’t enough, I knew I could go further.
Clock boost
I started by tweaking some timing constraints, re-synthesizing the FPGA bitstream, and up-clocking the FMC bus by 10%, from 125 to 137.5 MHz. I tried 150 originally but couldn’t get reliable read capture on the STM32 side; I think I need to use a more complex timing setup with separate PLL phases for launch and capture and this might need a faster FPGA to account for the reduced setup timing window when moving data from the PCLK domain to the launch clock.
But the faster bus had almost no impact on performance (throughput went from 284 to 286 Mbps). So I figured the bus was probably not the bottleneck and put no additional effort into closing timing at higher frequencies.
Initial performance measurements
I started out by adding some instrumentation to the FPGA to see how busy things actually were. (Tip for folks mostly doing networking/control type stuff on Xilinx FPGAs that don’t need a lot of multipliers: DSP48 blocks are great for 48-bit performance counters and come with basically zero area cost if your design doesn’t use them for anything else - I sprinkle them around like candy while optimizing! You just need the logic to implement readout of results but this is comparatively small, you can fit a 16:1 mux in a single 7-series slice.)
The APB bus load was quite low (around 27% of cycles occupied by transactions even with the iperf running), which makes sense given that the APB is 32 bits wide with a parallel address while the FMC is 16 with multiplexed address. Thus, unless there are other sources of APB traffic in the system, the internal APB will never be the bottleneck.
The FMC bus, however, was also not maxed out (only about 34% of cycles with CS# asserted, 48% busy after accounting for the two-cycle minimum latency with CS# high between transactions). This included about 9.3M register writes and 48K reads, so we can conclude that the majority of bus traffic is from pushing traffic to the Ethernet transmit buffer and not e.g. polling for inbound frames or doing other things the firmware does.
But since the bus is idle so much of the time, the bottleneck must be on the MCU.
Checksum optimization
I ran some profiling on the MCU (using the OpenOCD “profile” command) and determined that the UDP checksum calculation (no hardware offload in the current configuration, I may eventually try pushing to FPGA but that’s a separate issue) was using a fair bit of CPU time.
Here’s what it looked like starting out.
uint16_t IPv4Protocol::InternetChecksum(uint8_t* data, uint16_t len, uint16_t initial)
{
//Sum in 16-bit blocks until we run out
uint16_t* data16 = reinterpret_cast<uint16_t*>(data);
uint32_t checksum = initial;
while(len >= 2)
{
//Add with carry
checksum += __builtin_bswap16(*data16);
checksum = (checksum >> 16) + (checksum & 0xffff);
data16 ++;
len -= 2;
}
//Add the last byte if needed
if(len & 1)
{
checksum += __builtin_bswap16(*reinterpret_cast<uint8_t*>(data16));
checksum = (checksum >> 16) + (checksum & 0xffff);
}
return checksum;
}A lot of the common optimized software implementations depend on 2x 32-bit SIMD operations or similar, which aren’t available on Cortex-M, so I think I’m stuck using a 16 bit datapath. There’s probably some room for loop unrolling if needed.
But the most obvious optimization was to move the carry reduction to the end of the loop rather than reducing every iteration.
uint16_t IPv4Protocol::InternetChecksum(uint8_t* data, uint16_t len, uint16_t initial)
{
//Sum in 16-bit blocks until we run out
uint16_t* data16 = reinterpret_cast<uint16_t*>(data);
uint32_t checksum = initial;
while(len >= 2)
{
checksum += __builtin_bswap16(*data16);
data16 ++;
len -= 2;
}
//Add the last byte if needed
if(len & 1)
checksum += __builtin_bswap16(*reinterpret_cast<uint8_t*>(data16));
//Handle carry-out
while(checksum > 0xffff)
checksum = (checksum >> 16) + (checksum & 0xffff);
return checksum;
}This improved things slightly: up to 311 Mbps. FMC bus load was now 52% busy, but there was a lot more room.
DMA
The other thing the initial profiling pointed at me was the transmit logic, so I decided to implement DMA using the amusingly named MDMA (“master DMA”) peripheral on the STM32. I’m still refactoring some of my setup and abstraction code to make it a bit cleaner, but it’s functional now using raw register writes.
The DMA setup took some effort to get right because the frame data lives in DTCM (which is accessible to MDMA but not the regular DMA cores) and is intentionally misaligned by 16 bits (buffer pointer ends in 0x2, 0x6, 0xa, or 0xe). This is so that after accounting for the length of the 14 byte Ethernet frame header (6 bytes each src/dst MAC address and 2-byte ethertype), all of the upper layer protocol fields are aligned to 32 bit boundaries for easy processing by the TCP/IP stack.
Also, the current register map for my Ethernet TX FIFO requires one register write to a length field at the start, then writing the frame data, then writing to a “commit” register to actually send the frame. The explicit length allows full-width 32 bit bus transactions to be used even if the transport at some point in the bridge doesn’t have byte write enables (the extra 0-3 bytes at the end of the frame will be discarded by the FIFO and not sent to the MAC) and the commit ensures that frames being pushed at low rate and popped at gigabit by the MAC won’t underrun the buffer.
And since there’s no serialization guarantees for memory transactions from the CPU and the DMA executing in parallel, all of these writes have to come from the MDMA.
The configuration I ended up settling on for this test used the “linked list” mode of the MDMA to perform the three separate transfers sequentially. The frame transfer uses a pair of 16-bit reads on the AHBS port of the Cortex-M7 to read low and high halves of a 32-bit frame word from DTCM on two consecutive AHB clock cycles, which then gets turned into a single 32-bit AXI write going to the FMC, which ultimately ends up as a 32-bit APB write on the FPGA.
As of now the software side only supports a single outstanding frame (if you try to send another frame before the DMA finishes, it’ll block until the DMA channel is available) and the receive side is still just using a blocking loop. This will definitely get improved later on.
While this did improve the available parallelism, it resulted in a comparatively small improvement (327 Mbps and 62% bus load) in iperf performance.
The final push
I scratched my head a bit and then asked gprof to give me a line-by-line, rather than function level, dump of the hot spots from the profiling dump and it gave me weird errors rather than sensible output.
This was when I realized that gprof was lying to me thanks to optimizations, and I wasn’t actually tuning the hottest spot. I recompiled with -Og which produced a significantly smaller and slightly slower binary, but one that was far more amenable to instrumentation.
And this profiler report showed me that the real hot spot was in the code that filled the UDP application-layer content.
void Iperf3Server::FillPacket(int id, uint32_t* payload, uint32_t len)
{
uint32_t wordlen = len/4;
if(len % 4)
wordlen ++;
//Fill seconds and nanoseconds using our timer
auto countval = g_logTimer.GetCount();
auto sec = countval / 10000;
auto ticks = (countval % 10000);
auto us = ticks * 100;
payload[0] = __builtin_bswap32(sec);
payload[1] = __builtin_bswap32(us);
//Sequence number (for now only 32 bit)
//Increment first so sequence numbers in packet can be one-based
uint32_t seq = ++m_state[id].m_sequence;
payload[2] = __builtin_bswap32(seq);
payload[3] = 0;
//fill rest of packet with garbage
for(uint32_t i=4; i<wordlen; i++)
payload[i] = i;
}More specifically, the final “fill” loop, seen here in disassembly. I’m not entirely sure why it was so slow as I don’t know the details of the Cortex-M7 pipeline this well. Maybe something to do with coalescing dual 32-bit operations into 64-bit TCM accesses (or failing to do so due to lack of unrolling) or branch misprediction?
5a: d906 bls.n 6a <Iperf3Server::FillPacket(int, unsigned long*, unsigned long)+0x6a>
5c: 320c adds r2, #12
5e: 2304 movs r3, #4
60: f842 3f04 str.w r3, [r2, #4]!
64: 3301 adds r3, #1
66: 459c cmp ip, r3
68: d1fa bne.n 60 <Iperf3Server::FillPacket(int, unsigned long*, unsigned long)+0x60>One “#pragma GCC unroll 4” later, I had this. It seems to do a couple of branches early on using a code structure similar to Duff’s device that I guess is faster for the common case of all four iterations executing concurrently. You could probably make this even faster for typical large-ish packet sizes by moving the comparison out of the loop and doing the final iteration separately.
5a: d922 bls.n a2 <Iperf3Server::FillPacket(int, unsigned long*, unsigned long)+0xa2>
5c: f01e 0003 ands.w r0, lr, #3
60: f102 010c add.w r1, r2, #12
64: f04f 0304 mov.w r3, #4
68: d00f beq.n 8a <Iperf3Server::FillPacket(int, unsigned long*, unsigned long)+0x8a>
6a: 2801 cmp r0, #1
6c: d008 beq.n 80 <Iperf3Server::FillPacket(int, unsigned long*, unsigned long)+0x80>
6e: 2802 cmp r0, #2
70: d003 beq.n 7a <Iperf3Server::FillPacket(int, unsigned long*, unsigned long)+0x7a>
72: 4611 mov r1, r2
74: f841 3f10 str.w r3, [r1, #16]!
78: 2305 movs r3, #5
7a: f841 3f04 str.w r3, [r1, #4]!
7e: 3301 adds r3, #1
80: f841 3f04 str.w r3, [r1, #4]!
84: 3301 adds r3, #1
86: 459e cmp lr, r3
88: d00b beq.n a2 <Iperf3Server::FillPacket(int, unsigned long*, unsigned long)+0xa2>
8a: 1c5a adds r2, r3, #1
8c: 604b str r3, [r1, #4]
8e: 1d08 adds r0, r1, #4
90: 3302 adds r3, #2
92: 608a str r2, [r1, #8]
94: 3110 adds r1, #16
96: 6083 str r3, [r0, #8]
98: 1c93 adds r3, r2, #2
9a: 60c3 str r3, [r0, #12]
9c: 1cd3 adds r3, r2, #3
9e: 459e cmp lr, r3
a0: d1f3 bne.n 8a <Iperf3Server::FillPacket(int, unsigned long*, unsigned long)+0x8a>And the results were nothing short of astounding. 528 Mbps of UDP traffic and a saturated FMC bus, quite good for a 500 MHz single-core Cortex-M7 (now pushing just over one bit of Ethernet data per clock cycle)!
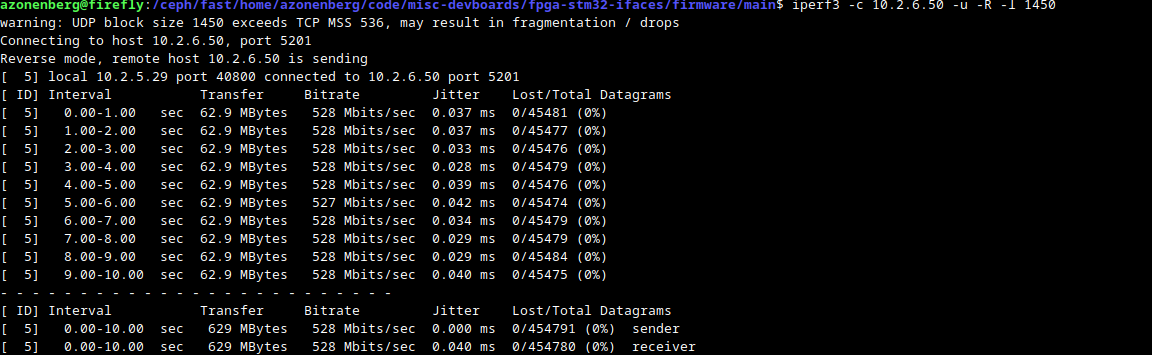
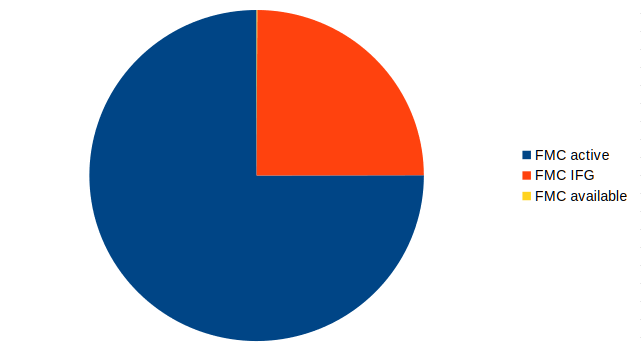
Conclusions
I’ve finally found the limit of the system and saturated the bus. Over half a Gbps of network traffic coming from a STM32H735 is more than I expect to ever need for any of my embedded management applications, and certainly far more CPU-FPGA bandwidth than I’ll need for anything I have in the pipeline.
I also fixed a few bugs in my APB and bridging code while working on this, including one causing the APB PSEL signal to be asserted for several clocks after PREADY when using pipeline stages, and another causing PADDR to be corrupted if two writes were issued back to back and the first one stalled for exactly the right number of clocks (the second write’s PADDR would be pushed to the bus controller before PREADY was asserted, causing the first write to go to the wrong address).
Now it’s time to move on to the next part of the project queue, assembling the new 48V IBC board and doing a bunch of decidedly not-fast power management firmware on the IBC as well as the supervisor MCU on the test board.
Like this post? Drop me a comment on Mastodon